

【Linux存储系列教程】glusterfs分布式文件系统
一、关于分布式文件系统
- 作用:
- 适用于海量数据
- 增加数据的处理速度
- 构建分布式文件存储系统常见的软件:
- hadoop, hdfs【大数据】
- glusterfs【云平台】
- ceph【现在比较流行】
1.gluster的特性
- 开源的
- 容量达到PB级、服务器的最多达到千台
- 提升数据读写速度、高用性
- 无元数据metadata的架构, 采用弹性hash定位数据
- 可以廉价的pc server上构建
2.gluster的结构
brick真实的存储空间,表现为磁盘挂载点
volume虚拟的存储空间,用于前端业务挂载使用

二、安装gluster分布式文件系统集群
准备:
5台虚拟机,master节点用于挂载后端node节点的volume,每台node节点添加4块虚拟硬盘
master01.linux.com 192.168.140.10
node1.linux.com 192.168.140.12
node2.linux.com 192.168.140.13
node3.linux.com 192.168.140.14
node4.linux.com 192.168.140.15
注:添加虚拟硬盘的时候,虚拟机应处于关机状态!

1.关闭防火墙和SElinux、设置时间同步
过程省略
2.配置免密SSH
在
node1上操作
[root@node1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:OG9ejEMDAz5S1uZbHkeU888zKWL7PmUSEKTqrsZmmLo root@node1
The key's randomart image is:
+---[RSA 2048]----+
| +. o+o |
| + .o .= |
| . ooo .. + |
| . ..=o . o |
| ++So + . |
| ..+.+o o O |
| + . =.oo = o |
| o =. o o. . |
|Eo +... . oo. |
+----[SHA256]-----+
[root@node1 ~]# mv /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.140.10:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.140.13:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.140.14:/root/
[root@node1 ~]# scp -r /root/.ssh/ root@192.168.140.15:/root/
3.配置主机名解析
[root@node1 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.140.10 master01.linux.com
192.168.140.12 node1.linux.com
192.168.140.13 node2.linux.com
192.168.140.14 node3.linux.com
192.168.140.15 node4.linux.com
把hosts文件拷贝给其他主机
利用
for循环快速拷贝过去
[root@node1 ~]# for i in 10 13 14 15
> do
> scp /etc/hosts root@192.168.140.$i:/etc/
> done
hosts 100% 322 91.2KB/s 00:00
hosts 100% 322 132.7KB/s 00:00
hosts 100% 322 130.7KB/s 00:00
hosts 100% 322 96.9KB/s 00:00
4.配置gluster软件仓库
[root@node1 ~]# vim /etc/yum.repos.d/gluster.repo
[gluster6]
name=gluster6
baseurl=https://mirrors.aliyun.com/centos/7.9.2009/storage/x86_64/gluster-6
enabled=1
gpgcheck=0
把仓库拷贝给其他虚拟机
[root@node1 ~]# for i in 10 13 14 15
> do
> scp /etc/yum.repos.d/gluster.repo root@192.168.140.$i:/etc/yum.repos.d/
> done
gluster.repo 100% 122 88.0KB/s 00:00
gluster.repo 100% 122 248.6KB/s 00:00
gluster.repo 100% 122 196.2KB/s 00:00
gluster.repo 100% 122 117.6KB/s 00:00
5.Node节点安装gluster
[root@node1 ~]# for i in 12 13 14 15
> do
> ssh root@192.168.140.$i yum install -y glusterfs-server glusterfs-fuse glusterfs
> done
设置开机自启动,并且检查服务运行状态
[root@node1 ~]# for i in 12 13 14 15
> do
> ssh root@192.168.140.$i systemctl enable --now glusterd
> ssh root@192.168.140.$i hostname; systemctl is-active glusterd
> done
6.Master节点安装gluster
因为我们
Master节点只需要挂载volume,不需要提供服务,所以不用安装glusterfs-server
[root@master01 ~]# yum install -y glusterfs glusterfs-fuse
7.创建gluster集群
回到
Node节点
[root@node1 ~]# for i in 2 3 4; do gluster peer probe node$i.linux.com; done
peer probe: success.
peer probe: success.
peer probe: success.
查看集群状态
任意一台
Node节点都可以
[root@node1 ~]# gluster peer status
Number of Peers: 3
Hostname: node2.linux.com
Uuid: 3525ea43-5105-4fdf-9733-1220b611eac0
State: Peer in Cluster (Connected) #已连接
Hostname: node3.linux.com
Uuid: d3707ddf-943c-4a09-b6fc-9933c8620835
State: Peer in Cluster (Connected) #已连接
Hostname: node4.linux.com
Uuid: 73392f76-fc7c-4fd9-809a-1697eeca3c89
State: Peer in Cluster (Connected) #已连接
三、格式化磁盘
1.格式化所有node节点后添加的4块硬盘
[root@node1 ~]# for i in 12 13 14 15
> do
> ssh root@192.168.140.$i mkfs -t xfs /dev/sdb
> ssh root@192.168.140.$i mkfs -t xfs /dev/sdc
> ssh root@192.168.140.$i mkfs -t xfs /dev/sdd
> ssh root@192.168.140.$i mkfs -t xfs /dev/sde
> done
2.创建挂载点(挂载目录)
[root@node1 ~]# for i in 12 13 14 15
> do
> ssh root@192.168.140.$i mkdir /data{1..4}
> done
3.配置永久挂载
[root@node1 ~]# vim /etc/fstab
/dev/sdb /data1 xfs defaults 0 0
/dev/sdc /data2 xfs defaults 0 0
/dev/sdd /data3 xfs defaults 0 0
/dev/sde /data4 xfs defaults 0 0
[root@node1 ~]# mount -a
[root@node1 ~]# df -hT
/dev/sdb xfs 20G 33M 20G 1% /data1
/dev/sdc xfs 20G 33M 20G 1% /data2
/dev/sdd xfs 20G 33M 20G 1% /data3
/dev/sde xfs 20G 33M 20G 1% /data4
其他node节点配置永久挂载
[root@node1 ~]# vim /etc/fstab
/dev/sdb /data1 xfs defaults 0 0
/dev/sdc /data2 xfs defaults 0 0
/dev/sdd /data3 xfs defaults 0 0
/dev/sde /data4 xfs defaults 0 0
[root@node1 ~]# mount -a
四、volume卷类型
1.分布式卷distributed volume

- 特征:
- 以单个文件为单位,分散存储到不同的
brick上
- 以单个文件为单位,分散存储到不同的
- 适用场景
- 海量
小文件存储,以增加读写速度
- 海量
- 容量
- 所有
brick之和,无brick数量限制
- 所有
A.创建brick
过程省略,刚刚我们已经提前创建过了
B.创建volume卷
[root@node1 ~]# gluster volume create dis_volume \
> node1.linux.com:/data1/br1 \
> node2.linux.com:/data1/br1
volume create: dis_volume: success: please start the volume to access data
C.启动volume卷
[root@node1 ~]# gluster volume start dis_volume
volume start: dis_volume: success
D.查看刚刚创建的volume卷信息
[root@node1 ~]# gluster volume info dis_volume
Volume Name: dis_volume
Type: Distribute
Volume ID: 23331fcc-65a6-4eba-a677-166755832a88
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data1/br1
Brick2: node2.linux.com:/data1/br1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
E.查看当前集群存在的volume卷
[root@node1 ~]# gluster volume list
dis_volume
F.Master主机测试挂载
[root@master01 ~]# mkdir /test1
[root@master01 ~]# vim /etc/fstab
node2.linux.com:/dis_volume /test1 glusterfs defaults,_netdev 0 0
#前面的节点写任意一个node都可以,只要在同一个集群下就可
[root@master01 ~]# mount -a
Master测试数据读写
[root@master01 ~]# touch /test1/{1..10}.mp3
[root@master01 ~]# ls /test1/
10.mp3 1.mp3 2.mp3 3.mp3 4.mp3 5.mp3 6.mp3 7.mp3 8.mp3 9.mp3
查看后台Node节点存储情况
适合海量小文件存储场景
[root@node1 ~]# ls /data1/br1/
1.mp3 2.mp3 3.mp3 7.mp3 8.mp3
[root@node2 ~]# ls /data1/br1/
10.mp3 4.mp3 5.mp3 6.mp3 9.mp3
2.复制卷replicate volume

- 特征
- 以单个文件为单位,每个文件会被复制多份存储
- 提升数据可靠性
- 浪费
1/2存储空间 replicas指定的复制数量与brick数量一致
A.创建brick
过程省略,刚刚我们已经提前创建过了
B.创建volume卷
replicas指定的复制数量与brick数量一致
[root@node1 ~]# gluster volume create repli_volume replica 3 \
> node1.linux.com:/data2/br1 \
> node2.linux.com:/data2/br1 \
> node3.linux.com:/data2/br1
volume create: repli_volume: success: please start the volume to access data
C.启动volume卷
[root@node1 ~]# gluster volume start repli_volume
volume start: repli_volume: success
D.查看volume卷信息
[root@node1 ~]# gluster volume info repli_volume
Volume Name: repli_volume
Type: Replicate
Volume ID: 36df6979-e86d-467f-b7dd-9ab399c0717f
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3 #每存一份数据,将被复制成3份存到后端brick上
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data2/br1
Brick2: node2.linux.com:/data2/br1
Brick3: node3.linux.com:/data2/br1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
E.查看当前集群所有卷组
[root@node1 ~]# gluster volume list
dis_volume
repli_volume
F.Master节点挂载测试
[root@master01 ~]# mkdir /test2
[root@master01 ~]# vim /etc/fstab
node3.linux.com:/repli_volume /test2 glusterfs defaults,_netdev 0 0
[root@master01 ~]# mount -a
测试数据读写
[root@master01 ~]# touch /test2/{1..10}.txt
[root@master01 ~]# ls /test2
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
查看后端Node节点
可以看到数据被复制了三份
[root@node1 ~]# ls /data2/br1/
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
[root@node2 ~]# ls /data2/br1/
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
[root@node3 ~]# ls /data2/br1/
10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
3.分布式复制卷Distributed-replicate
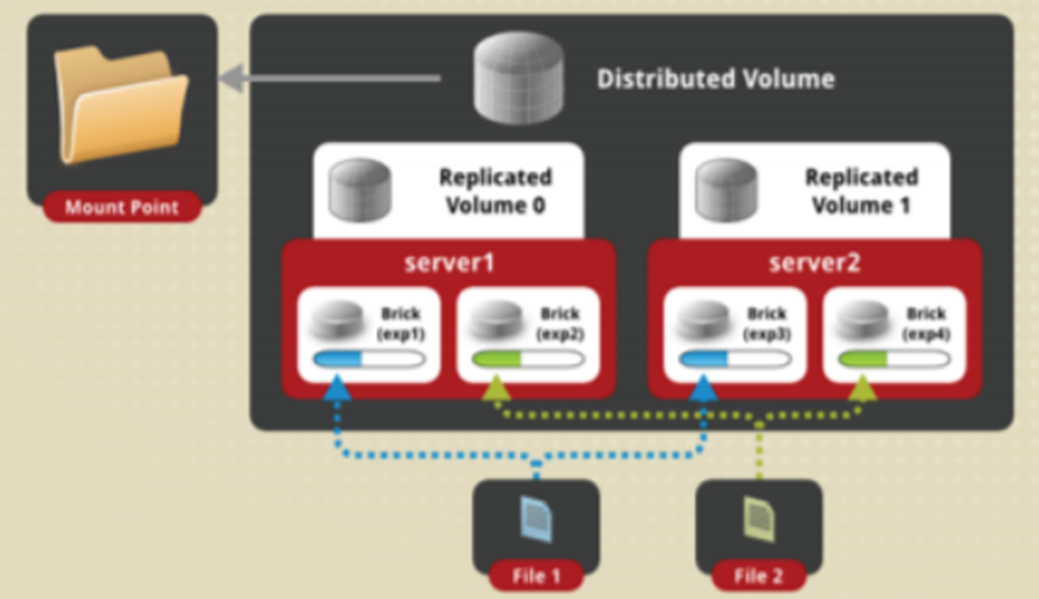
- 特征
- 所有文件分散存储,不同的文件再进行复制
- 适用场景
- 适用于小文件存储,提升可靠性
brick数量为replica参数的整倍数
A.创建brick
过程省略,刚刚我们已经提前创建过了
B.创建volume卷
replicas指定的复制数量与brick数量一致
[root@node1 ~]# gluster volume create dis_repli_volume replica 2 \
> node1.linux.com:/data3/br1 \
> node2.linux.com:/data3/br1 \
> node3.linux.com:/data3/br1 \
> node4.linux.com:/data3/br1
C.启动volume卷
[root@node1 ~]# gluster volume start dis_repli_volume
volume start: dis_repli_volume: success
D.查看volume卷详细信息
[root@node1 ~]# gluster volume info dis_repli_volume
Volume Name: dis_repli_volume
Type: Distributed-Replicate
Volume ID: aeae303f-51dd-402f-9017-29d00bc9d416
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data3/br1
Brick2: node2.linux.com:/data3/br1
Brick3: node3.linux.com:/data3/br1
Brick4: node4.linux.com:/data3/br1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
E.查看当前集群volume卷
[root@node1 ~]# gluster volume list
dis_repli_volume
dis_volume
repli_volume
F.Master节点挂载
[root@master01 ~]# mkdir /test3
[root@master01 ~]# vim /etc/fstab
node1.linux.com:/dis_repli_volume /test3 glusterfs defaults,_netdev 0 0
[root@master01 ~]# mount -a
测试数据读写
[root@master01 ~]# touch /test3/{1..10}.jpg
[root@master01 ~]# ls /test3
10.jpg 1.jpg 2.jpg 3.jpg 4.jpg 5.jpg 6.jpg 7.jpg 8.jpg 9.jpg
查看后端Node节点
[root@node1 ~]# ls /data3/br1/
2.jpg 4.jpg 6.jpg 7.jpg 8.jpg 9.jpg
[root@node2 ~]# ls /data3/br1/
2.jpg 4.jpg 6.jpg 7.jpg 8.jpg 9.jpg
[root@node3 ~]# ls /data3/br1/
10.jpg 1.jpg 3.jpg 5.jpg
[root@node4 ~]# ls /data3/br1/
10.jpg 1.jpg 3.jpg 5.jpg
4.分散卷Disperse
- 特征:
- 单个文件会被拆成多部分分散存储, 同时存储数据的校验码
- 适用场景
- 存储大文件,提升速度
disperse用于指定brick数量redundany指定用于保存校验码的brick数量,不指定的话,gluster集群会自动选定brick数量用于保存校验码
A.创建brick
过程省略,刚刚我们已经提前创建过了
B.创建volume卷
disperse要和brick相等
[root@node1 ~]# gluster volume create disperse_volume disperse 4 \
> node1.linux.com:/data4/br1 \
> node2.linux.com:/data4/br1 \
> node3.linux.com:/data4/br1 \
> node4.linux.com:/data4/br1
There isn't an optimal redundancy value for this configuration. Do you want to create the volume with redundancy 1 ? (y/n) y
#如果不手动指定redundany,工具会自动帮我们按照brick的数量划分
volume create: disperse_volume: success: please start the volume to access data
C.启动volume卷
[root@node1 ~]# gluster volume start disperse_volume
volume start: disperse_volume: success
D.查看volume卷详细信息
[root@node1 ~]# gluster volume info disperse_volume
Volume Name: disperse_volume
Type: Disperse
Volume ID: c0aa03de-a23a-49d3-a7bc-443e938df5d4
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x (3 + 1) = 4 #一份数据会被分成3份,其中另外1份为校验码
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data4/br1
Brick2: node2.linux.com:/data4/br1
Brick3: node3.linux.com:/data4/br1
Brick4: node4.linux.com:/data4/br1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
E.查看当前集群的所有volume卷
[root@node1 ~]# gluster volume list
dis_repli_volume
dis_volume
disperse_volume
repli_volume
F.Master节点挂载
[root@master01 ~]# mkdir /test4
[root@master01 ~]# vim /etc/fstab
node4.linux.com:/disperse_volume /test4 glusterfs defaults,_netdev 0 0
#节点随便哪个都可以,只要在同一个集群下即可
[root@master01 ~]# mount -a
测试数据读写
[root@master01 ~]# dd if=/dev/zero of=/test4/file01 bs=1M count=20
[root@master01 ~]# dd if=/dev/zero of=/test4/file02 bs=1M count=20
[root@master01 ~]# dd if=/dev/zero of=/test4/file03 bs=1M count=20
[root@master01 ~]# ls -lh /test4
总用量 61M
-rw-r--r-- 1 root root 20M 5月 5 19:56 file01
-rw-r--r-- 1 root root 20M 5月 5 19:56 file02
-rw-r--r-- 1 root root 20M 5月 5 19:56 file03
查看后端Node节点
[root@node1 ~]# ls -lh /data4/br1/
总用量 22M
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file01
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file02
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file03
[root@node2 ~]# ls -lh /data4/br1/
总用量 23M
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file01
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file02
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file03
[root@node3 ~]# ls -lh /data4/br1/
总用量 21M
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file01
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file02
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file03
[root@node4 ~]# ls -lh /data4/br1/
总用量 23M
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file01
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file02
-rw-r--r-- 2 root root 6.7M 5月 5 19:56 file03
五、扩容卷容量
1.扩展卷容量
扩展分布复制卷时,添加的
brick数量是replica参数的整倍数
2.扩容分布式卷
[root@node1 ~]# gluster volume add-brick dis_volume \
> node3.linux.com:/data1/br1
volume add-brick: success
注意扩容卷后,还要
rebalance一下,否则新的brick不会存储数据
[root@node1 ~]# gluster volume rebalance dis_volume start
可以使用
status查看状态
[root@node1 ~]# gluster volume rebalance dis_volume status
Node Rebalanced-files size scanned failures skipped status run time in h:m:s
--------- ----------- ----------- ----------- ----------- ----------- ------------ --------------
node2.linux.com 2 0Bytes 5 0 0 completed 0:00:00
node3.linux.com 0 0Bytes 0 0 0 completed 0:00:00
localhost 2 0Bytes 5 0 0 completed 0:00:00
volume rebalance: dis_volume: success
3.Master节点测试
[root@master01 ~]# touch /test1/{1..20}.img
[root@master01 ~]# ls /test1
10.img 12.img 15.img 18.img 1.mp3 2.mp3 4.img 5.mp3 7.img 8.mp3
10.mp3 13.img 16.img 19.img 20.img 3.img 4.mp3 6.img 7.mp3 9.img
11.img 14.img 17.img 1.img 2.img 3.mp3 5.img 6.mp3 8.img 9.mp3
4.查看后端Node节点
可以看到新添的
node3已经有数据了
[root@node1 ~]# ls /data1/br1/
11.img 12.img 13.img 15.img 16.img 17.img 18.img 1.mp3 2.mp3 3.img 5.img 8.mp3
[root@node2 ~]# ls /data1/br1/
10.img 10.mp3 14.img 19.img 20.img 4.mp3 8.img 9.img 9.mp3
[root@node3 ~]# ls /data1/br1/
1.img 2.img 3.mp3 4.img 5.mp3 6.img 6.mp3 7.img 7.mp3
六、缩减卷容量
缩减分布复制卷时,缩减的
brick数量是replica参数的整倍数
1.缩减分布式卷
在缩减容量之前,一定要提前转移里面的数据,
gluster会自动做转移数据的操作
[root@node1 ~]# gluster volume remove-brick dis_volume \
> node3.linux.com:/data1/br1 start
2.查看状态
[root@node1 ~]# gluster volume remove-brick dis_volume node3.linux.com:/data1/br1 status
Node Rebalanced-files size scanned failures skipped status run time in h:m:s
--------- ----------- ----------- ----------- ----------- ----------- ------------ --------------
node3.linux.com 9 0Bytes 9 0 0 completed 0:00:00
3.查看卷详细信息
此时
node3并没有被踢出去
[root@node1 ~]# gluster volume info dis_volume
Volume Name: dis_volume
Type: Distribute
Volume ID: 23331fcc-65a6-4eba-a677-166755832a88
Status: Started
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data1/br1
Brick2: node2.linux.com:/data1/br1
Brick3: node3.linux.com:/data1/br1
Options Reconfigured:
performance.client-io-threads: on
transport.address-family: inet
nfs.disable: on
[root@node3 ~]# ls /data1/br1/
[root@node3 ~]# #确认node3上面的数据已经转移走了
4.提交修改
[root@node1 ~]# gluster volume remove-brick dis_volume node3.linux.com:/data1/br1 commit
volume remove-brick commit: success
Check the removed bricks to ensure all files are migrated.
If files with data are found on the brick path, copy them via a gluster mount point before re-purposing the removed brick.
5.再次查看卷详细信息
此时已经没有
node3了
[root@node1 ~]# gluster volume info dis_volume
Volume Name: dis_volume
Type: Distribute
Volume ID: 23331fcc-65a6-4eba-a677-166755832a88
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data1/br1
Brick2: node2.linux.com:/data1/br1
Options Reconfigured:
performance.client-io-threads: on
transport.address-family: inet
nfs.disable: on
七、替换故障卷Replace faulty brick
1.替换分布卷的brick
- 添加新
brick(不需要手动rebalance) - 删除旧
brick
2.替换旧的故障卷
[root@node1 ~]# gluster volume replace-brick repli_volume node3.linux.com:/data2/br1 node4.linux.com:/data2/br1 commit force
3.查看卷详细信息
[root@node1 ~]# gluster volume info repli_volume
Volume Name: repli_volume
Type: Replicate
Volume ID: 36df6979-e86d-467f-b7dd-9ab399c0717f
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: node1.linux.com:/data2/br1
Brick2: node2.linux.com:/data2/br1
Brick3: node4.linux.com:/data2/br1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
八、设置卷的参数
gluster volume set <VOLNAME> <OPT-NAME> <OPT-VALUE>
1.常用参数
- 基于IP地址认证
- auth.allow
- auth.reject
- performance.write-behind-window-size
- 设置写缓冲区Buffer大小,默认1M
- performance.io-thread-count
- 设置卷的IO线程数量 1–64
- performance.cache-size
- 设置卷的缓存大小
- performance.cache-max-file-size
- 设置缓存的最大文件大小
- performance.cache-min-file-size
- 设置缓存的最小文件大小
- performance.cache-refresh-timeout
- 设置缓存区的刷新时间间隔, 单位秒
更多参数详情请到官网查看:https://docs.gluster.org/en/latest/Administrator-Guide/Tuning-Volume-Options/
【Linux存储系列教程】glusterfs分布式文件系统
https://www.wsjj.top/archives/103
评论