

在Windows系统上使用WSL部署vLLM开源大模型框架
点我跳转到下一篇教程使用MaxKB搭建一个本地知识库系统
一、写在最前面
本教程在开始前,需要读者确认您的Windows版本是否为专业版,以及硬件性能水平是否达到相应的需求,教程将使用NVIDIA显卡作为示范。
本教也适用于在Linux系统上部署vLLM,只需跳过前面安装WSL步骤和自行安装NVIDIA Linux版显卡驱动即可。
二、开启Windows系统的WSL2功能
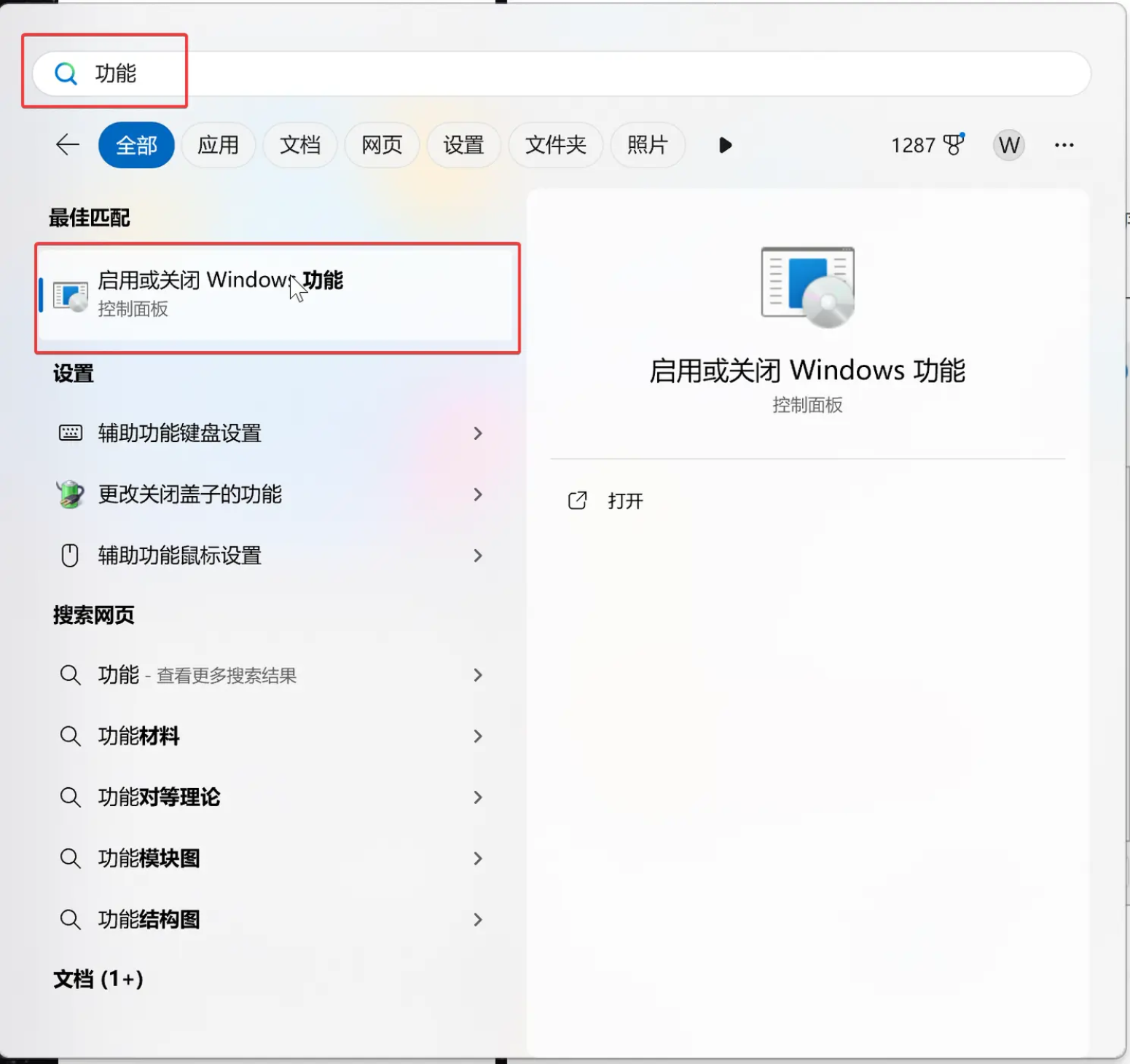
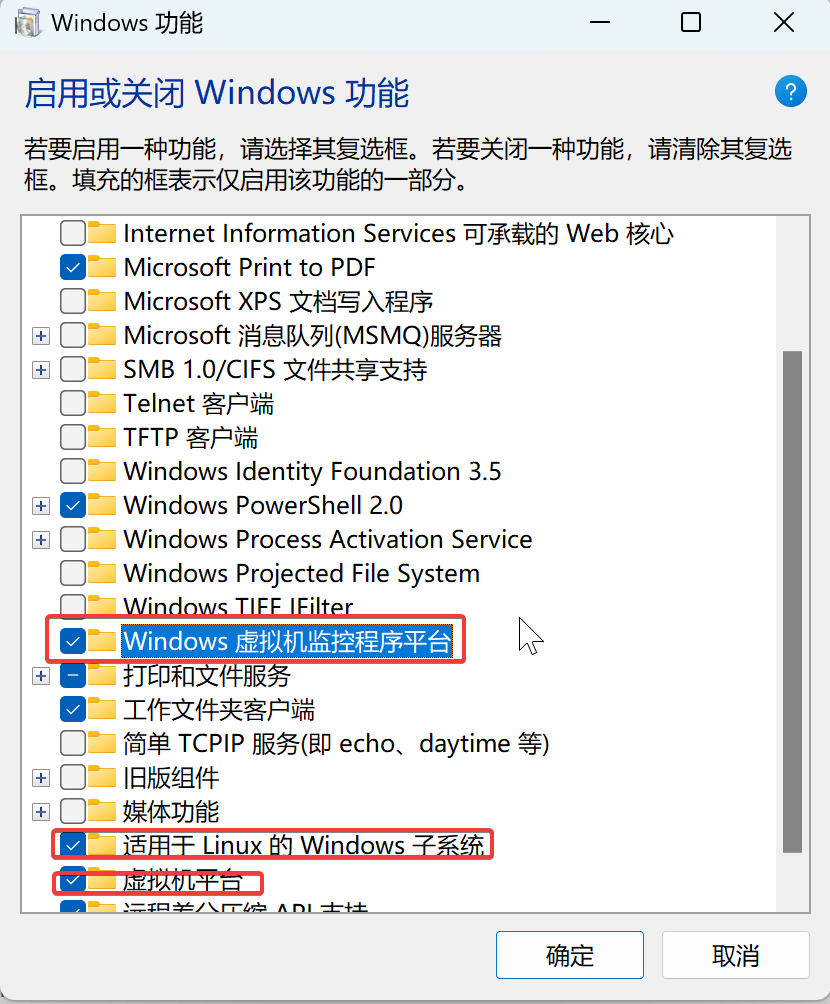
1.启用WSL功能
按照图上操作,并且重启系统后即可
2.设置WSL2为默认版本
使用win+R运行打开powershell
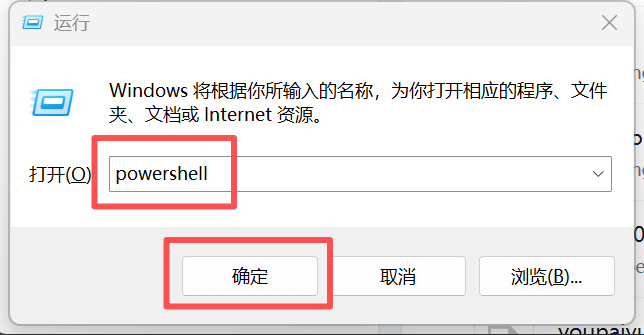
在powershell中输入以下指令
wsl --set-default-version 2
3.升级下载WSL2的组件
wsl --update
升级完成后自行重启系统
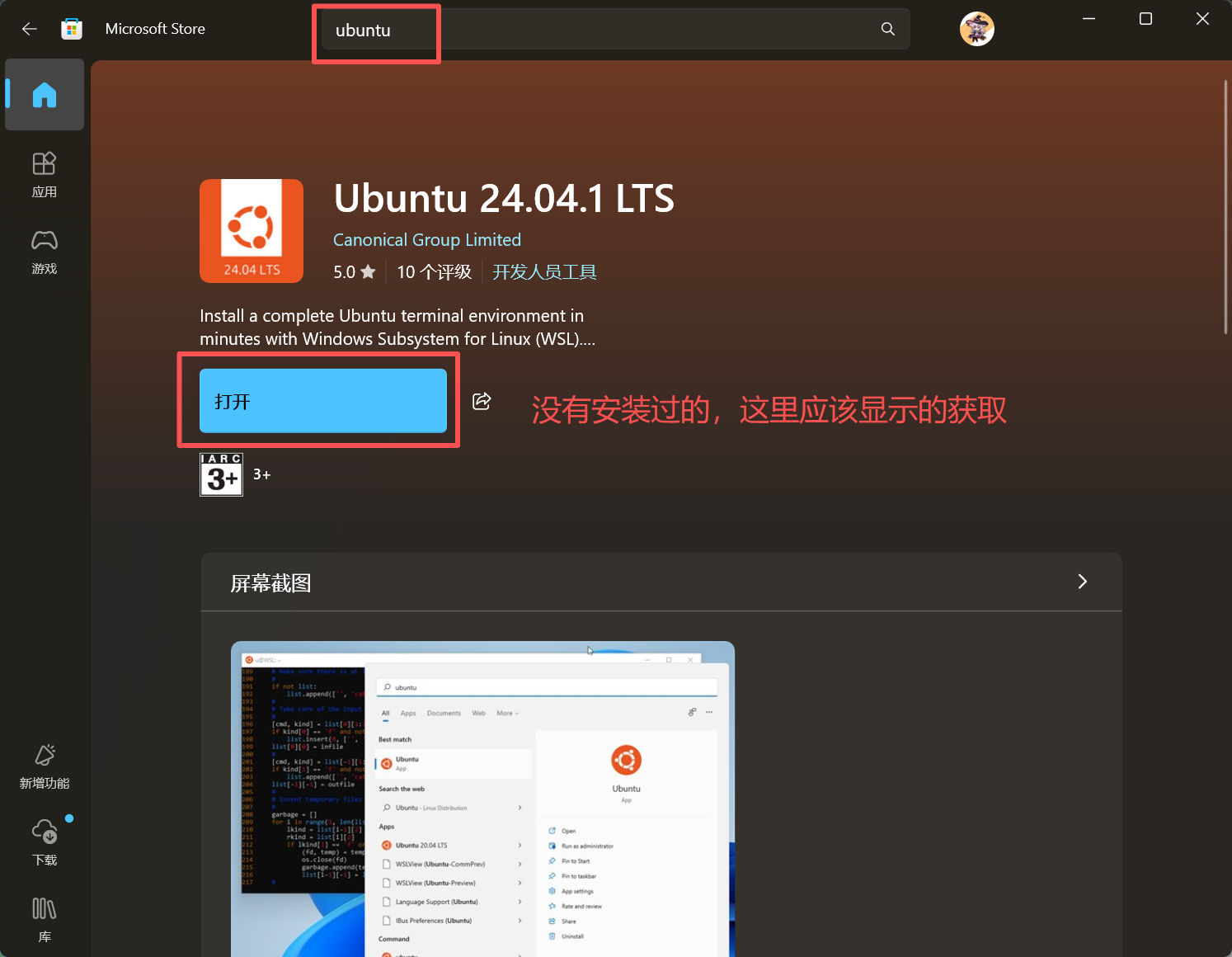
三、安装Ubuntu系统
重启完成后,可在微软商店中选择自己想要的Linux发行版本,我这里使用Ubuntu24.04进行演示。
四、配置Ubuntu镜像源
Ubuntu安装完成并且成功启动,应该是下图样式
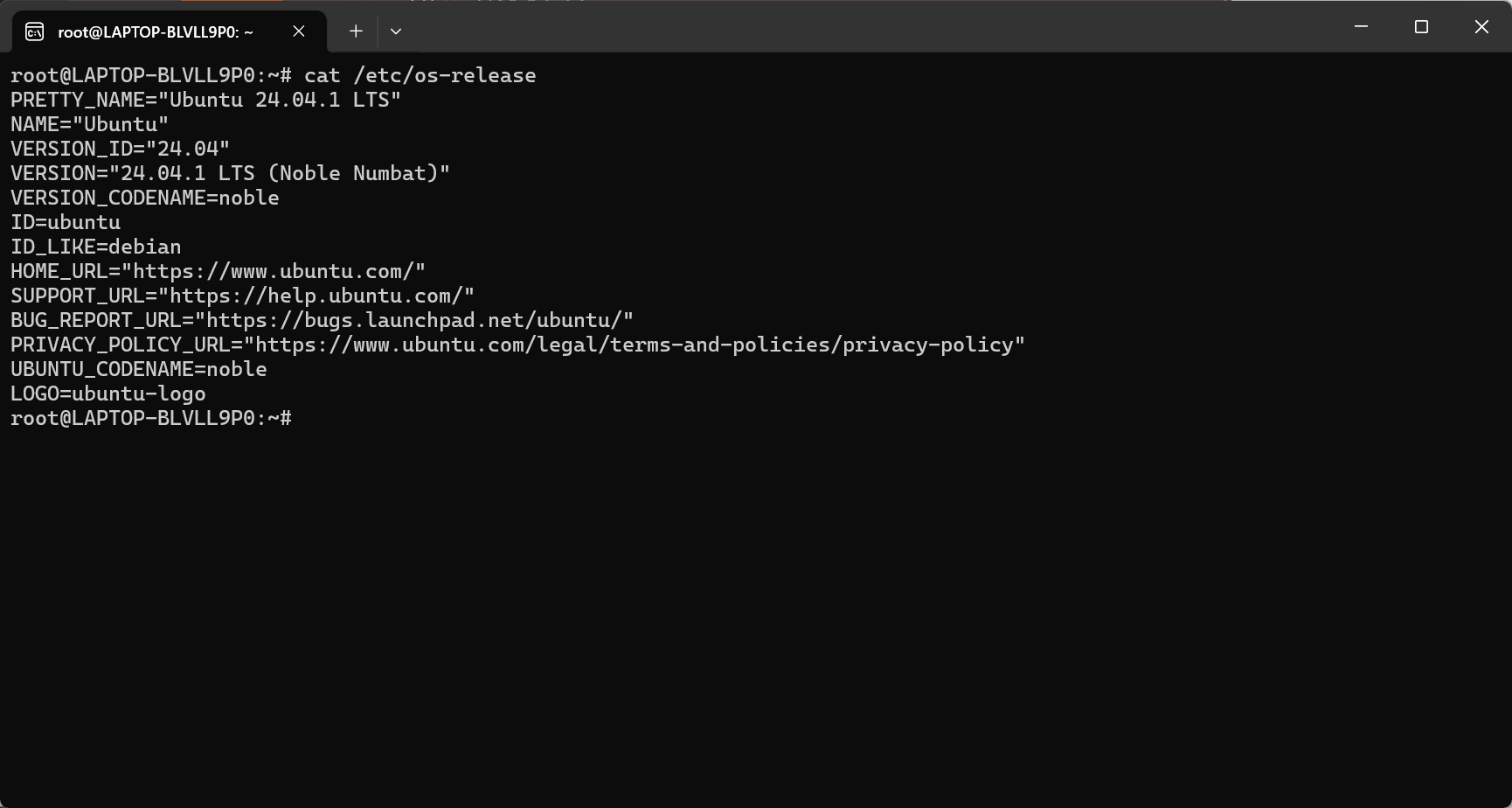
可以使用以下命令查看发行版本信息
cat /etc/os-release
配置系统镜像加速源为阿里云,并且更新系统和镜像源
sed -i 's|http://.*archive.ubuntu.com|https://mirrors.aliyun.com|g' /etc/apt/sources.list.d/ubuntu.sources
sed -i 's|http://.*security.ubuntu.com|https://mirrors.aliyun.com|g' /etc/apt/sources.list.d/ubuntu.sources
apt update && apt upgrade -y #这一步可能会很慢
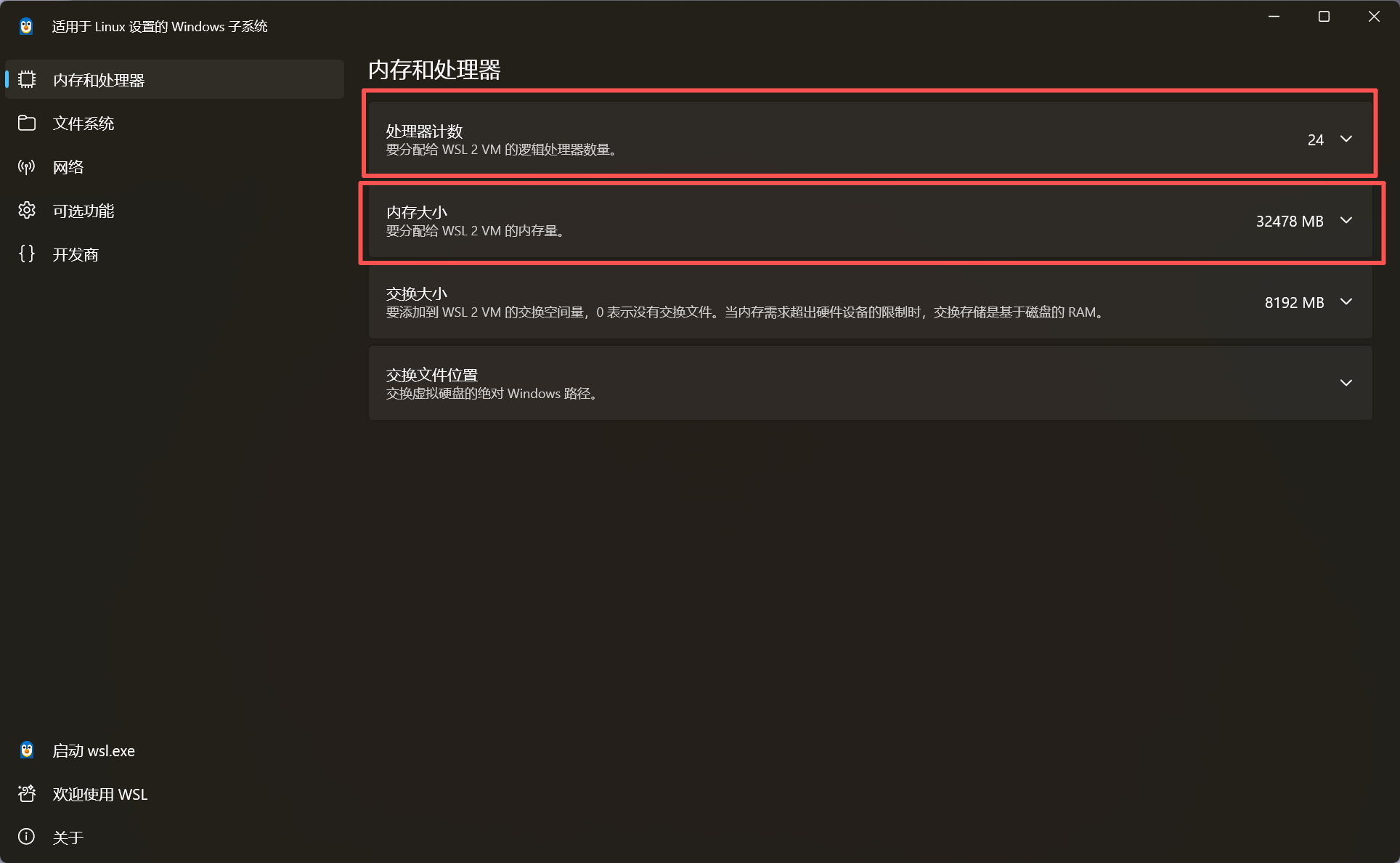
配置虚拟机的内存大小
您可以通过以下图示,根据您自己的计算机配置动态调整
五、移动WSL虚拟机位置(重要)
此步骤是把默认C盘的虚拟机,转移到您自己清楚的位置,目的是接下来可以更好的管理虚拟机
#请使用win+R打开powershell输入以下命令
#导出ubuntu
wsl --export Ubuntu-24.04 D:\WSL\Ubuntu.tar
#注销旧的系统
wsl --unregister Ubuntu-24.04
#导入新的系统到D:\WSL\Ubuntu下
wsl --import Ubuntu D:\WSL\Ubuntu D:\WSL\Ubuntu.tar
#启用发行版系统
wsl -d Ubuntu
#查看当前系统所有发行版
wsl --list
到此为止,一个完整的Linux系统就已经安装在Windows系统内了。
六、安装NVIDIA显卡驱动和CUDA加速工具
注意:安装显卡驱动,不需要在WSL环境中安装,只需要您的Windows系统有NVIDIA的显卡驱动即可。
也可以前往英伟达官网下载自己对应显卡型号的最新版驱动https://www.nvidia.cn/geforce/drivers/
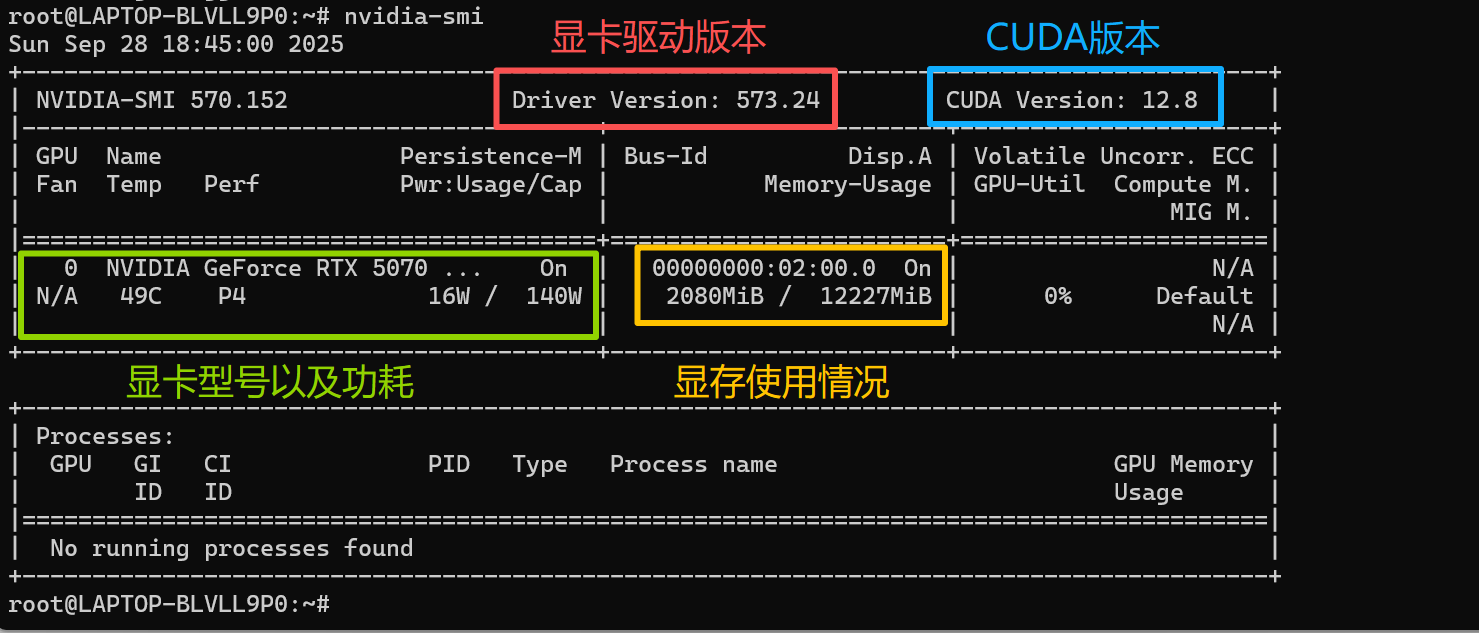
1.验证您的显卡驱动版本和CUDA版本
在ubuntu中输入以下指令,并且返回如图所示
nvidia-smi
2.根据提示下载对应的CUDA版本
注意安装CUDA工具包不同于显卡驱动,CUDA需要在Ubuntu环境中安装
访问以下网址获取下载链接https://developer.nvidia.com/cuda-toolkit-archive
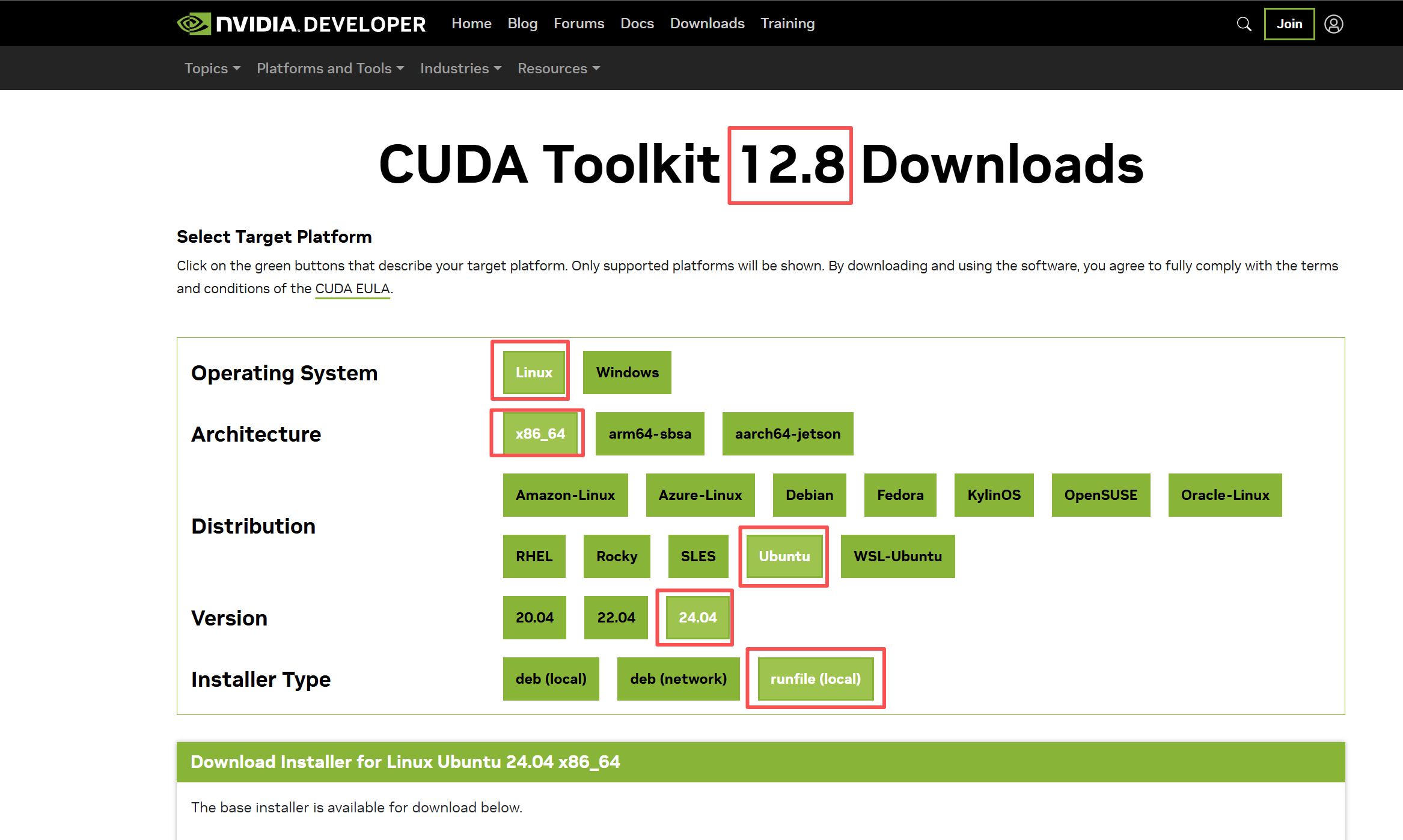
根据网页提示在Ubuntu中输入代码即可
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
sudo sh cuda_12.8.0_570.86.10_linux.run
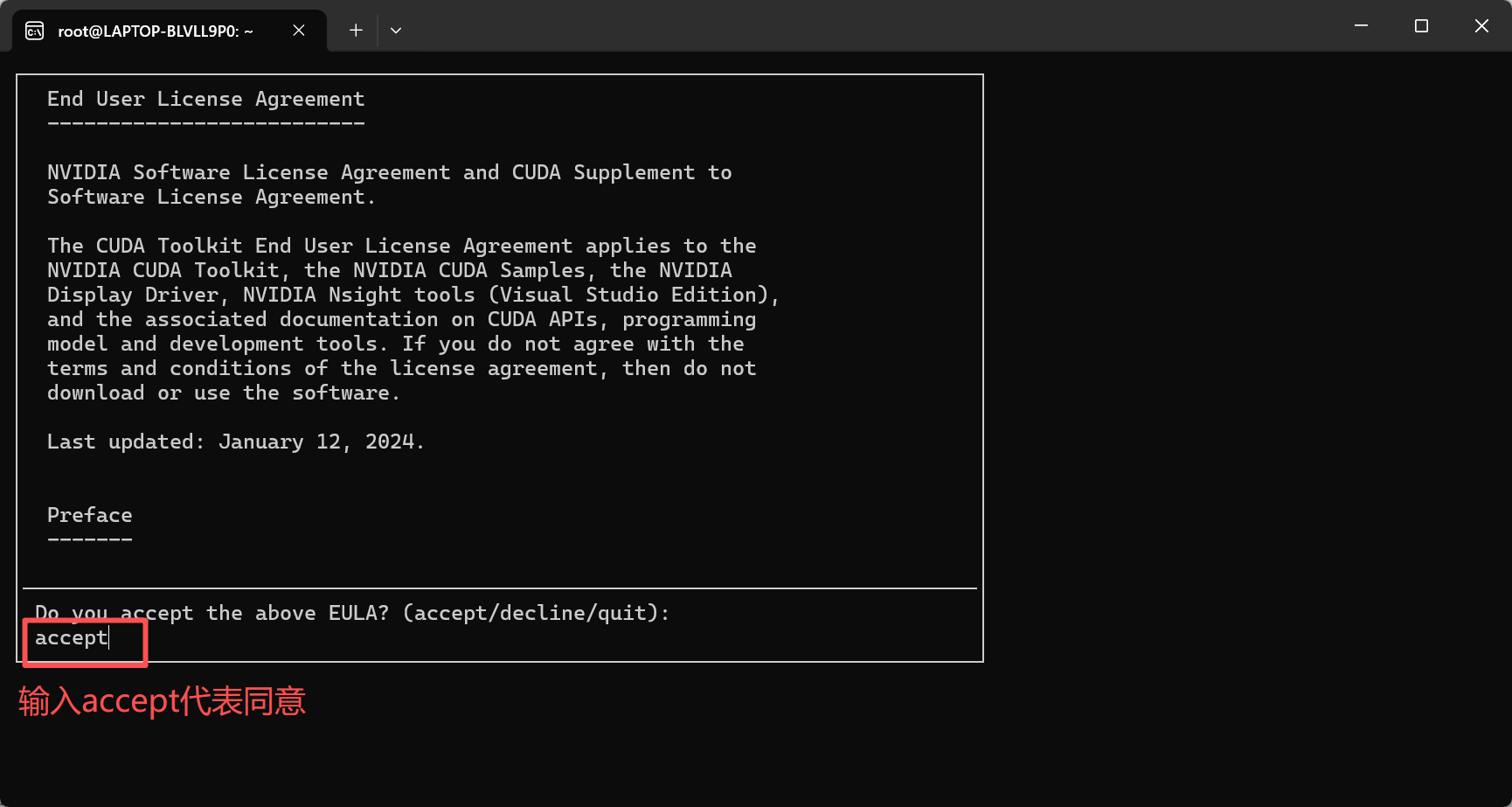
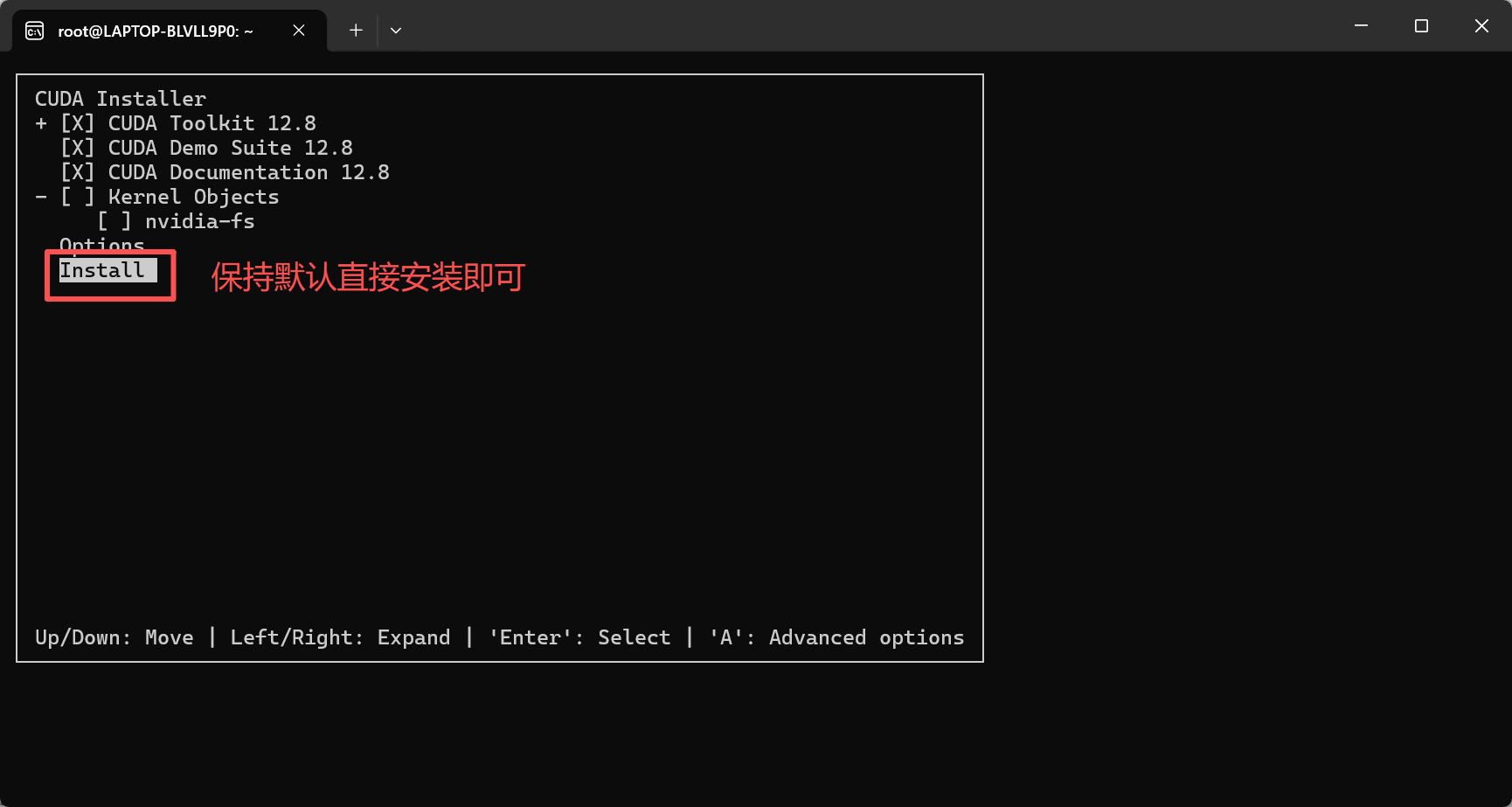
安装完后添加环境变量
vim /etc/bash.bashrc
#把下面的内容添加到文件最底部,如果您不习惯使用VIM编辑器可以选择您习惯的命令
export PATH=/usr/local/cuda-12.8/bin/:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64/:$LD_LIBRARY_PATH
#然后输入下面的命令
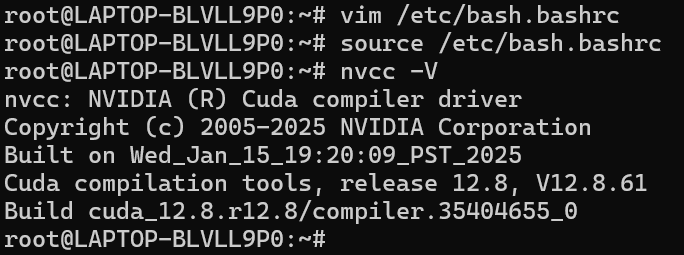
source /etc/bash.bashrc
nvcc -V
安装成功如下图所示
3.如果遇到报错,可以根据我的方法排查问题(无报错的跳过此步骤)
如下图所示,CUDA安装失败,并且把错误信息都保存在了/var/log/cuda-installer.log这个日志文件中
首先看一下错误日志中有什么内容
cat /var/log/cuda-installer.log
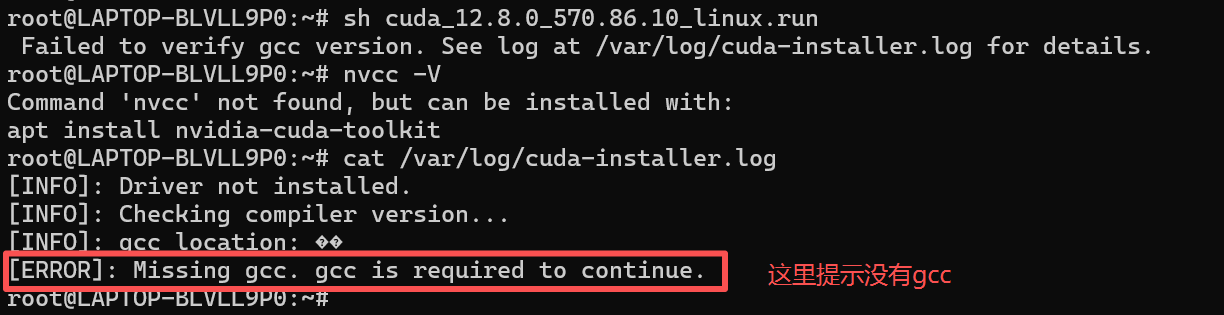
我们根据错误日志的提示,安装相应的软件包试试
apt install -y make gcc g++
之后再重新运行一遍安装程序测试
sudo sh cuda_12.8.0_570.86.10_linux.run
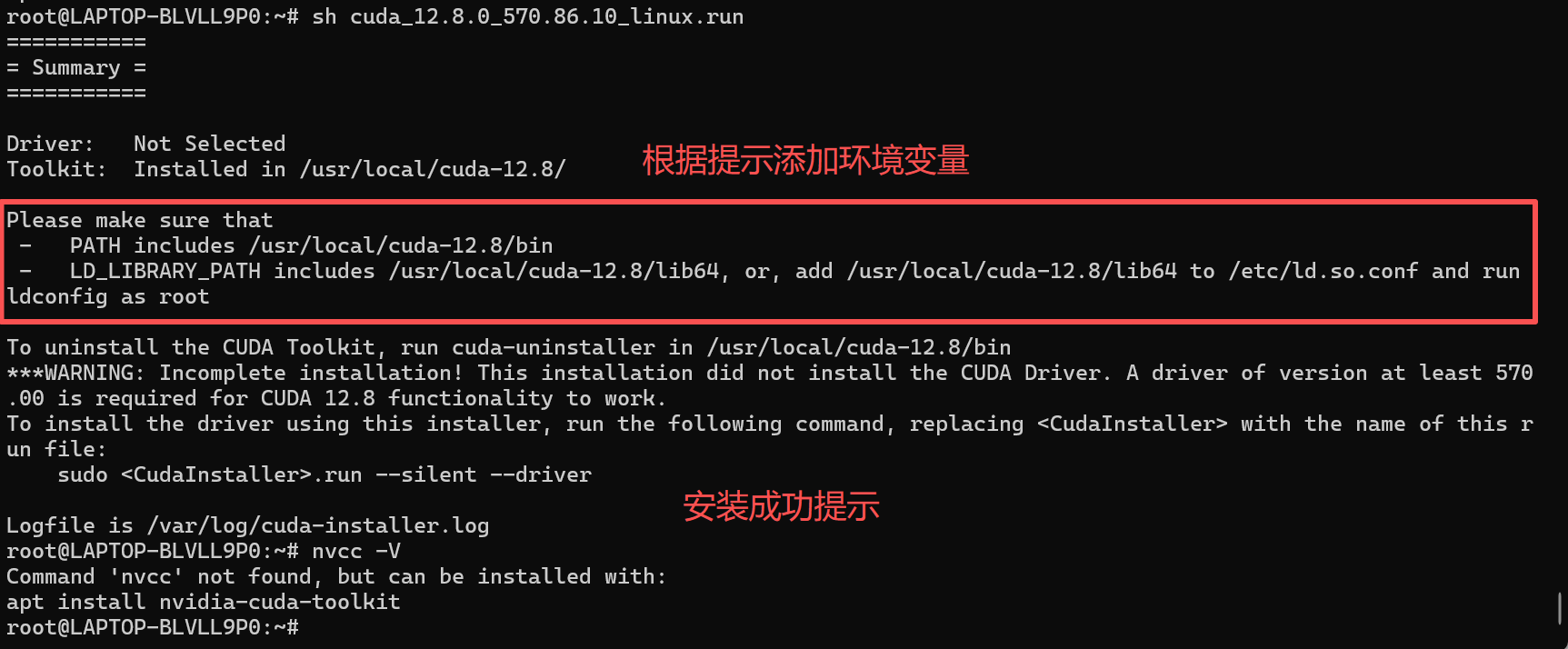
安装完后添加环境变量
vim /etc/bash.bashrc
#把下面的内容添加到文件最底部,如果您不习惯使用VIM编辑器可以选择您习惯的命令
export PATH=/usr/local/cuda-12.8/bin/:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64/:$LD_LIBRARY_PATH
#然后输入下面的命令
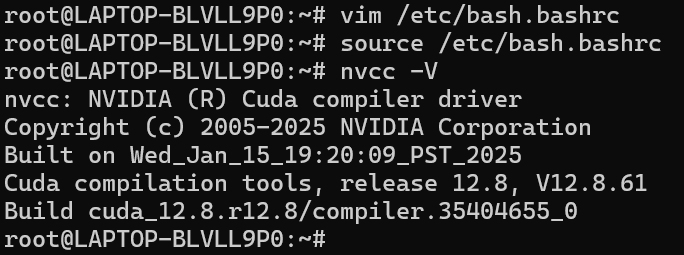
source /etc/bash.bashrc
nvcc -V
安装成功如下图所示
4.安装CuDNN加速包
请根据您自己的环境选择相应版本的安装包https://developer.nvidia.com/rdp/cudnn-download
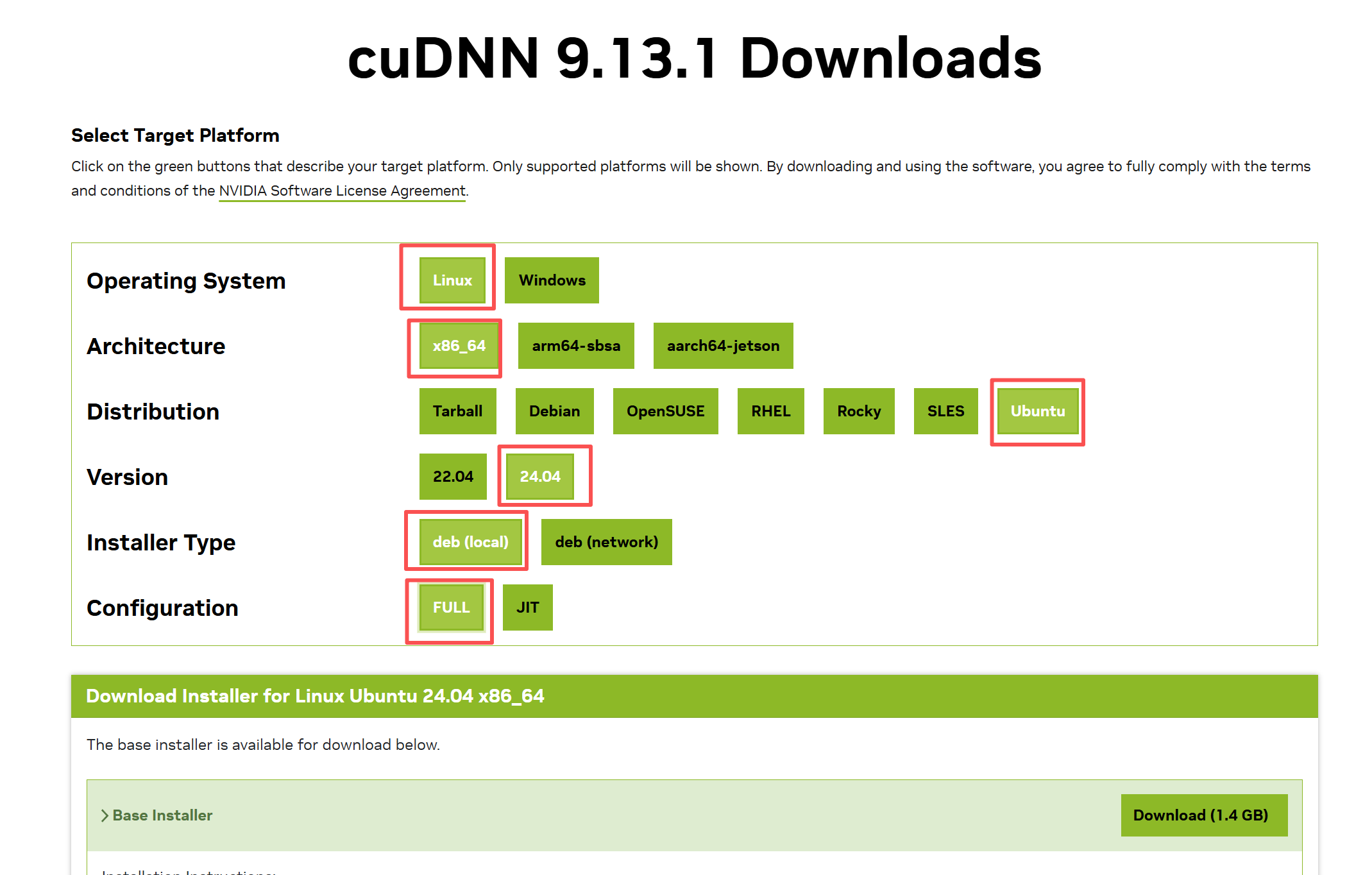
wget https://developer.download.nvidia.com/compute/cudnn/9.13.1/local_installers/cudnn-local-repo-ubuntu2404-9.13.1_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2404-9.13.1_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2404-9.13.1/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
验证CuDNN是否成功安装
输入下面的两行代码,如果返回结果,那就安装成功了
ls /usr/lib/x86_64-linux-gnu/libcudnn.so*
cat /usr/include/x86_64-linux-gnu/cudnn_version.h | grep CUDNN_MAJOR -A 2
七、安装vLLM
1.安装Anaconda
curl -O https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh | sh
2.添加conda加速源
conda config --add channels conda-forge
conda config --set show_channel_urls yes
如果上面的源不可用,可以试试下面的
vim ~/.condarc
#把里面的内容清空输入下面的内容
channels:
- nodefaults
custom_channels:
conda-forge: https://mirrors.ustc.edu.cn/anaconda/cloud
bioconda: https://mirrors.ustc.edu.cn/anaconda/cloud
show_channel_urls: true
3.创建虚拟环境并激活
我这里测试过很多Python版本,最后只有Python3.11成功安装了,所以建议不要使用太高的Python版本
conda create -n vllm-env python=3.11
conda activate vllm-env
4.安装NVIDIA加速包和pip
conda install -c nvidia cudatoolkit
conda update pip
#测试python版本和pip版本
(vllm-env) root@LAPTOP-BLVLL9P0:~# python --version
Python 3.11.0
(vllm-env) root@LAPTOP-BLVLL9P0:~# pip --version
pip 22.3.1 from /root/anaconda3/envs/vllm-env/lib/python3.11/site-packages/pip (python 3.11)
5.配置pip加速源
mkdir -p ~/.pip
cat > ~/.pip/pip.conf << EOF
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
timeout = 6000
EOF
6.安装git和gcc
这段是我后加上的,防止安装vllm过程中出现各种奇奇怪怪的报错
apt install -y git make gcc g++
7.安装vLLM
pip install torch
pip install vllm
pip install -U huggingface_hub #此模块用于直接在huggingface上下载模型
export HF_ENDPOINT=https://hf-mirror.com #配置huggingface镜像加速站
8.测试vllm版本
(vllm-env) root@LAPTOP-BLVLL9P0:~# vllm -v
INFO 10-01 19:49:01 [__init__.py:216] Automatically detected platform cuda.
0.10.2 #此版本是截止教程编写日期的最新版本
八、部署一个本地模型
1.下载模型到本地
我这里使用DeepSeek作为测试模型,如果想要其他模型,可以访问这个镜像站https://hf-mirror.com/
mkdir -p ~/app/models/deepseek-r1
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir ~/app/models/deepseek-r1 --local-dir-use-symlinks False
| 参数 | 详情 |
|---|---|
| --resume-download | 指定下载的模型 |
| --local-dir | 模型保存路径 |
| --local-dir-use-symlinks | 禁用软连接 |
2.创建api服务
vllm serve /root/app/models/deepseek-r1 \
--api-key abc123456 \
--served-model-name deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--max-model-len 2048 \
--gpu-memory-utilization 0.4 \
--block-size 8 \
--max-num-batched-tokens 512 \
--max-num-seqs 2 \
--port 7890
| 参数 | 详情 |
|---|---|
| --api-key | 验证秘钥 |
| --served-model-name | 指定模型名字 |
| --max_model_len | 最大上下文 |
| --port | 指定运行端口 |
| --tensor-parallel-size 2 | 指定2张卡运行模型 |
| --quantization awq | 使用awq量化 |
| --gpu-memory-utilization | 设置模型占用显存大小 |
| --chat-template | 指定聊天模板 |
3.本地测试
curl http://127.0.0.1:7890/v1/completions \.1:7890/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer abc123456" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"prompt": "Hello, how are you?",
"max_tokens": 50,
"temperature": 0.7
}'
如果返回结果,那么恭喜你,一个简单的deepseek本地调用成功运行!
点我跳转到下一篇教程使用MaxKB搭建一个本地知识库系统
【AI大模型系列教程】在Windows系统上使用WSL部署vLLM开源大模型框架
https://www.wsjj.top/archives/vllm
评论