
【容器应用系列教程】Kubernetes介绍
一、Kubernetes介绍
1.Kubernetes是什么
- 是容器编排工具
- 由
google公司开源的应用,基于go语言编写 - 简称
k8s
2.Kubernetes的作用
- 服务发现和负载均衡
- 存储编排
- 自动部署和回滚
- 资源调度分配
- 自我修复
总而言之,
kubernetes的目的就是让容器部署应用变得更简单、高效
二、Kubernetes组件介绍
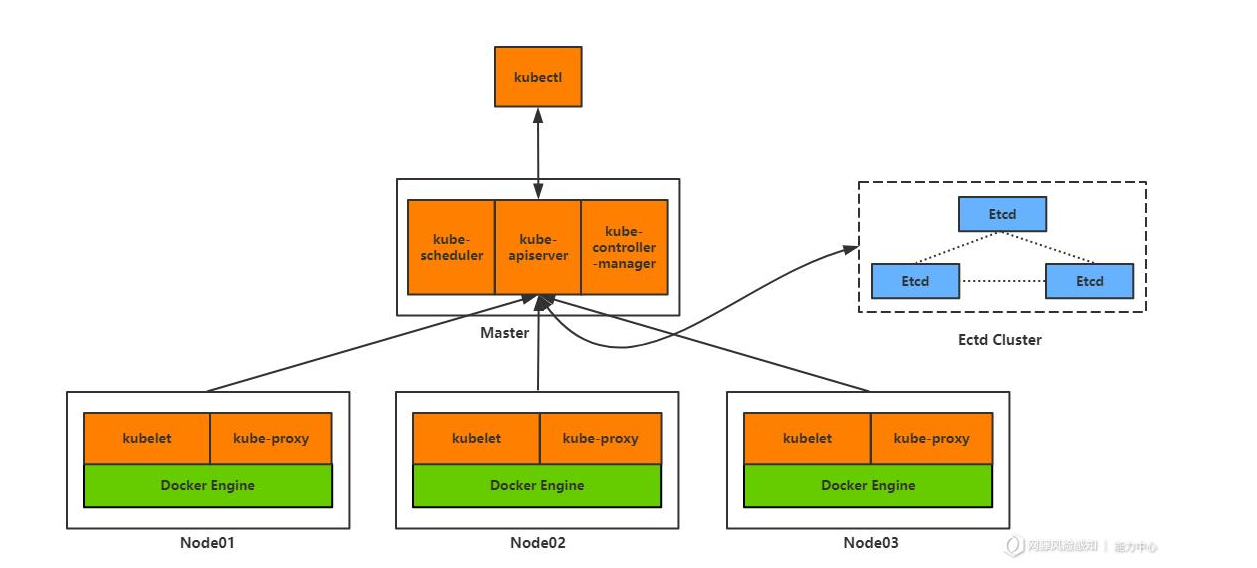
1.Master节点
Master负责管理整个集群。Master协调集群中的所有活动,例如调度应用、维护应用的所需状态、应用扩容以及推出新的更新
API Server组件
- 与
etcd数据库进行交互,读写集群状态信息 - 接收客户端操作请求, 验证身份
- 接收
kubelet发送过来的注册请求
Scheduler组件
- 调度客户端操作请求,选择合适的
Node节点运行资源
Controller Manager组件
- 管理集群控制器,例如
replication controller负责维护容器的副本数量
2.Node节点
运行
pod的主机,可以是物理服务器,也可以是虚拟机
处理生产级流量的Kubernetes集群至少应具有三个Node
container engine组件
容器引擎
K8s支持包括Docker和Podman在内的主流容器管理软件
kubelet组件
- 调度容器引擎创建容器
kube-proxy组件
- 在多个容器间实现负载均衡(LVS)
- 同样负责容器的发布服务(iptables)
3.etcd数据库
记录集群状态数据,例如
node节点信息、pod信息、service等
同样也是k8s环境中,最重要的部分
三、Kubernets组件详解
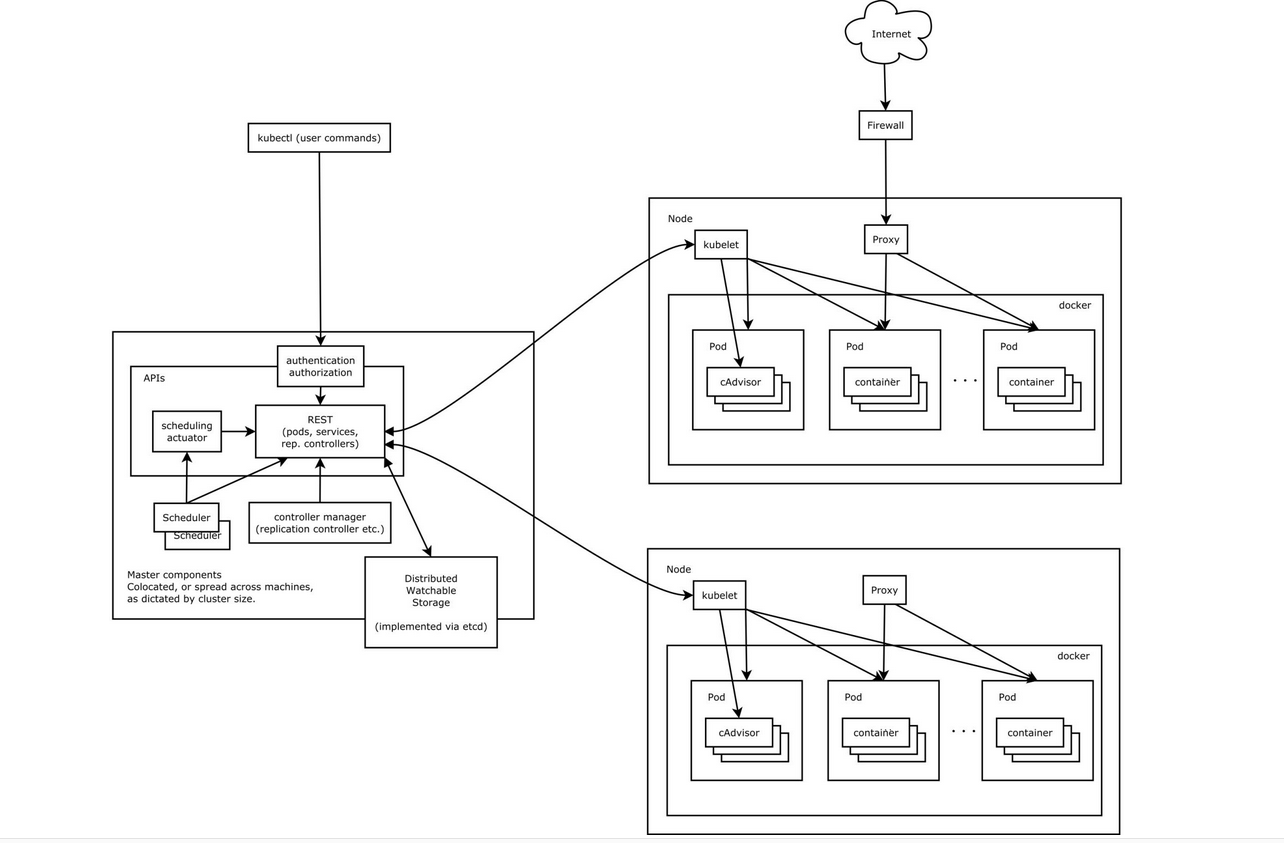
通过k8s集群创建一个pod的过程说明组件间的交互过程
- 用户通过客户端工具向
api server组件发送创建pod`的请求 api server接收到该请求后,会将请求信息(pod名称、镜像、卷、网络等信息)记录到etcd数据库scheduler组件会周期性的请求api server,以询问是否有操作请求api server组件查询etcd数据库响应scheduler组件,scheduler组件会得知存在创建pod的请求scheduler按一定的算法选择一个合适的node节点计划创建Pod, 并将选定的节点信息返回给api server;api server会将该node节点要与创建的pod对应关系写入etcd数据库kublet组件启动后,会先api server注册自己,以让api server得知有运行起kublet服务的node节点的存在,并将node节点信息记录到etcd数据库;这样scheduler组件才可以根据数据库的记录选择合适的节点创建podkubelet组件也会周期性的请求api server, 以询问是否有自己要做的操作,api server查询数据库响应kubelet,kubelet获知到要创建的pod的信息后,调用container engine创建容器- 容器创建完成后,为便于访问,由
kube-proxy提供负载均衡
三、Kubernetes集群对象
1.Node
运行
pod的主机,可以是物理服务器,也可以是虚拟机;每个node节点上都要运行容器引擎(docker或rkt)、kubelet组件及kube-proxy组件
2.Namespace
命名空间,是资源或对象的抽象集合
kubernetes集群默认会自动创建3个namespace
- default——默认namespace
- kube-system
- k8s集群内部组件
- kube-public
3.Container
容器
4.Pod
kubernetes所能管理的最小单元, 一个pod中可以放一个容器,也可以放多个容器pod的设计理念是支持多个容器在一个pod中共享网络地址和文件系统k8s集群会为每个pod分配一个IP,称为podIP- 从实际应用角度讲,多数应用都是一个
pod中只放一个容器 - 本质上讲,
k8s创建一个pod后,每个Pod中至少存在两个容器,一个是用户自定义的容器,另一个是k8s自动创建的名称为pause-amd64的容器, 实际上Pod的IP是配置在pause容器上的
5.Label
- 一个
key-value键值对的数据结构,用于在k8s集群中标识对象;例如每创建一个pod都应该为其分配一个或多个label - 一个对象可以被分配一个
label或多个label label分配完成后,k8s集群会使用Label selector来选择具有相同标签的一组资源
6.Annotations
key-value键值对的数据结构,用于为对象添加注释说明信息- 默认情况下可以不写
- 在特殊应用场景下,可以通过
Annotations辅助部署应用;例如特定的镜像结合特定的说明信息时
7.Replication Controller复制控制器 RC
RC是k8s集群中保证Pod高可用的对象。通过监控运行中的Pod来保证集群中运行指定数量的Pod副本RC通过Label Selector机制实现对Pod副本的自动控制
8.Replica Set 副本集 RS
RS是新一代的RC,提供同样的高可用能力。
9.Deployment部署
- 通过
Deployment来管理集群中的RS、Pod - 在实际操作中,很少直接去操作
RS或Pod,在k8s集群中要完成对RS和Pod的管理,都是通过操作Deployment完成 Deployment自动创建RS保证Pod副本- 在升级操作时,
Deployment会做滚动升级 - 在升级操作时,如果检测到升级失败,会自动回滚
10.HPA Horizontal Pod Autoscaler
- 用于实现
Pod自动横向扩容 HPA会实时监测RC中的Pod的负载情况,完成自动扩展- 可通过
CPU百分比、自定义指标QPS实现
11.Service服务
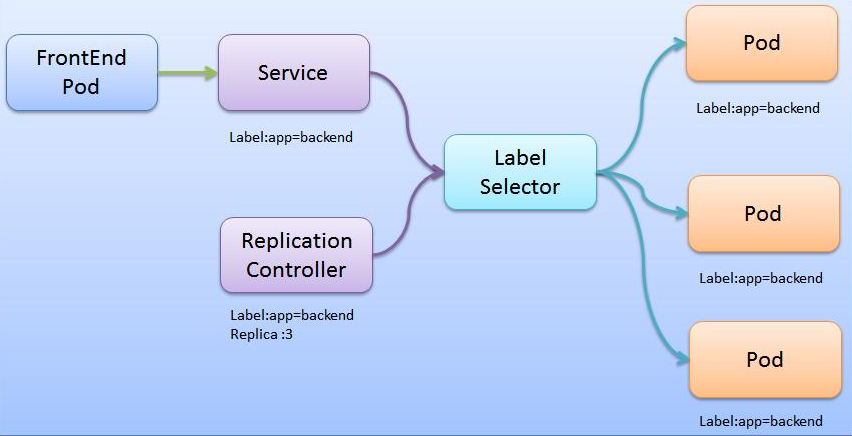
- 将具有相同
label的Pod标记为一组,由集群为service分配固定IP,便于用户访问 - 可以理解为一个
service是一组具有相同标签的Pod的集合 - 由
kube-proxy组件实现,kube-proxy创建service类似于负载均衡器,后端Pod类似于real server Pod宕机产生新Pod时,kube-proxy会自动更新etcd数据库关于service与Pod的对应关系
12.服务发现
- 借助
DNS实现,coreDNS组件 - 创建
service时,k8s集群会为其分配一个域名www.default.svc.cluster.local - 域名格式:
- 服务名称.命名空间.svc.cluster.local
service创建完成后,会自动形成IP与域名的解析关系,集群内多个service相互通信时,依靠域名实现
13.Job任务
k8s集群执行批处理任务的对象- 用于运行一次性任务,任务成功完成后
Pod自动退出,类似于一次性计划任务
14.DaemonSet
- 保证选定的业务在所有的节点运行一个
Pod - 典型场景:监控
agent, 日志收集工具filebeat
15.StatefulSet有状态服务
- 通过
Statefulset创建的Pod,集群会为其分配一个固定的名称,而且该名称创建后是不能修改的、也是集群全局唯一的;用于让构建业务集群的多个Pod间通过名称通信,而不是借助IP,来保证服务的有状态性 stateful的实现要依赖于存储volume,例如一个Pod挂载一个独立的存储,该Pod宕机后,自动创建一个新的Pod,新Pod一样会去挂载存储获取数据,这就相当于新Pod继承的原有Pod的所有数据及状态- 典型应用场景:数据库集群
16.Volume卷
用于实现数据持久化保存
17.Federation集群联邦
- 存在多个不同的
k8s集群时,常规情况下,我们连接哪个集群创建资源,资源就会被创建在哪个集群里 Federation基于全局控制器,可实现将多个不同的集群放到一个全局控制器中,创建资源时,向该全局控制器发送请求,全局控制器会选择一个集群创建资源Fderation基于全局调度器,在访问资源时,向全局调度器发送请求,它会将请求转交到合适的集群处理
【容器应用系列教程】Kubernetes介绍
https://www.wsjj.top/archives/137
评论